During winter 2012, Netflix suffered an extended outage that lasted for seven hours because of issues within the AWS Elastic Load Balancer service within the US-East area. (Netflix runs on Amazon Web Services [AWS]—we haven’t any information facilities of our personal. All of your interactions with Netflix are served from AWS, besides the precise streaming of the video. Once you click on “play,” the precise video recordsdata are served from our personal CDN.) During the outage, not one of the visitors going into US-East was reaching our providers.
To forestall this from occurring once more, we determined to construct a system of regional failovers that’s resilient to failures of our underlying service suppliers. Failover is a technique of defending laptop techniques from failure during which standby tools mechanically takes over when the principle system fails.
Regional failovers decreased the chance
We expanded to a complete of three AWS areas: two within the United States (US-East and US-West) and one within the European Union (EU). We reserved sufficient capability to carry out a failover in order that we will soak up an outage of a single area.
A typical failover appears to be like like this:
- Realize that one of many areas is having bother.
- Scale up the 2 savior areas.
- Proxy some visitors from the troubled area to the saviors.
- Change DNS away from the issue area to the savior areas.
Let’s discover every step.
1. Identify the difficulty
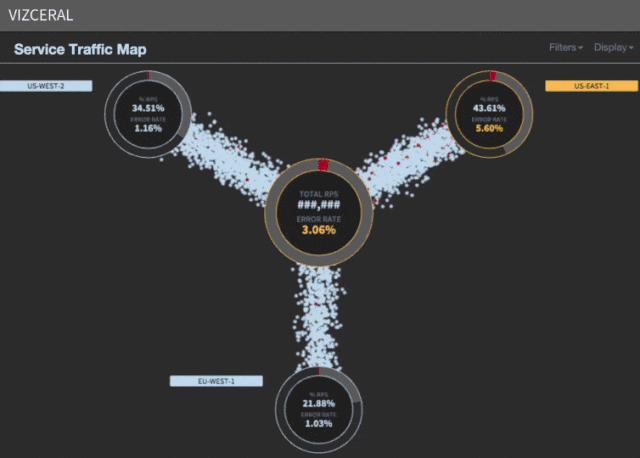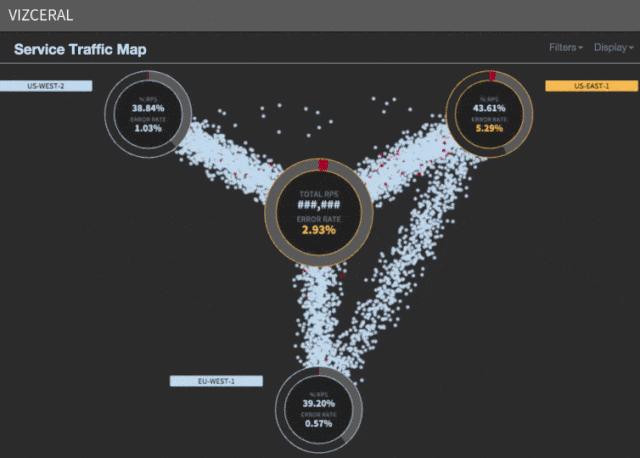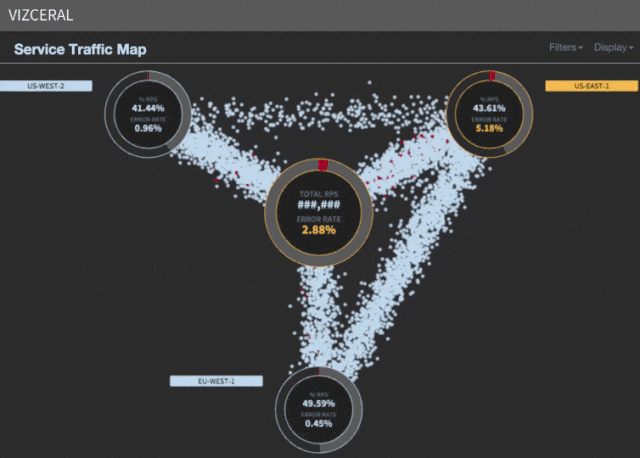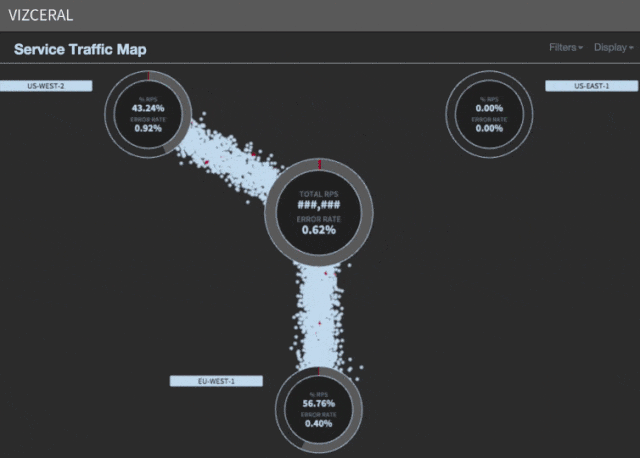
We want metrics, and ideally a single metric, that may inform us the well being of the system. At Netflix, we use a enterprise metric known as stream begins per second (SPS for brief). This is a rely of the variety of purchasers which have efficiently began streaming a present.
We have this information partitioned per area, and at any given time we will plot the SPS information for every area and evaluate it towards the SPS worth from the day earlier than and the week earlier than. When we discover a dip within the SPS graph, we all know our prospects will not be capable of begin streaming reveals, thus we’re in bother.
The bother is not essentially a cloud infrastructure concern. It may very well be a nasty code deploy in one of many lots of of microservices that make up the Netflix ecosystem, a lower in an undersea cable, and many others. We could not know the rationale; we merely know that one thing is flawed.
If this dip in SPS is noticed solely in a single area, it is an incredible candidate for regional failover. If the dip is noticed in a number of areas, we’re out of luck as a result of we solely have sufficient capability to evacuate one area at a time. This is exactly why we stagger the deployment of our microservices to 1 area at a time. If there’s a drawback with a deployment, we will evacuate instantly and debug the problem later. Similarly, we need to keep away from failing over when the issue would comply with the visitors redirection (like would occur in a DDoS assault.)
2. Scale up the saviors
Once we have now recognized the sick area, we should always prep the opposite areas (the “saviors”) to obtain the visitors from the sicko. Before we activate the hearth hose we have to scale the stack within the savior areas appropriately.
What does scaling appropriately imply on this context? Netflix’s visitors sample is just not static all through the day. We have peak viewing hours, normally round 6-9pm But 6pm arrives at completely different occasions in several elements of the world. The peak visitors in US-East is three hours forward of US-West, which is eight hours behind the EU area.
When we failover US-East, we ship visitors from the Eastern U.S. to the EU and visitors from South America to US-West. This is to scale back the latency and supply the absolute best expertise for our prospects.
Taking this into consideration, we will use linear regression to foretell the visitors that shall be routed to the savior areas for that point of day (and day of week) utilizing the historic scaling habits of every microservice.
Once we have now decided the suitable measurement for every microservice, we set off scaling for every of them by setting the specified measurement of every cluster after which let AWS do its magic.
three. Proxy visitors
Now that the microservice clusters have been scaled, we begin proxying visitors from the sick area to the savior areas. Netflix has constructed a high-performance, cross-regional edge proxy known as Zuul, which we have now open sourced.
These proxy providers are designed to authenticate requests, do load shedding, retry failed requests, and many others. The Zuul proxy also can do cross-region proxying. We use this characteristic to route a trickle of visitors away from the struggling area, then progressively improve the quantity of rerouted visitors till it reaches 100%.
This progressive proxying permits our providers to make use of their scaling insurance policies to do any reactive scaling essential to deal with the incoming visitors. This is to compensate for any change in visitors quantity between the time once we did our scaling predictions and the time it took to scale every cluster.
Zuul does the heavy lifting at this level to route all incoming visitors from a sick area to the wholesome areas. But the time has come to desert the affected area fully. This is the place the DNS switching comes into play.
four. Switch the DNS
The final step within the failover is to replace the DNS information that time to the affected area and redirect them to the wholesome areas. This will fully transfer all consumer visitors away from the sick area. Any purchasers that do not expire their DNS cache will nonetheless be routed by the Zuul layer within the affected area.
That’s the background info of how failover used to work at Netflix. This course of took a very long time to finish—about 45 minutes (on an excellent day).
Speeding response with shiny, new processes
We seen that majority of the time (roughly 35 minutes) was spent ready for the savior areas to scale. Even although AWS might provision new cases for us in a matter of minutes, beginning up the providers, doing just-in-time warm-up, and dealing with different startup duties earlier than registering UP in discovery dominated the scaling course of.
We determined this was too lengthy. We wished our failovers to finish in below 10 minutes. We wished to do that with out including operational burden to the service house owners. We additionally wished to remain cost-neutral.
We reserve capability in all three areas to soak up the failover visitors; if we’re already paying for all that capability, why not use it? Thus started Project Nimble.
Our thought was to keep up a pool of cases in scorching standby for every microservice. When we’re able to do a failover, we will merely inject our scorching standby into the clusters to take dwell visitors.
The unused reserved capability known as trough. A number of groups at Netflix use a number of the trough capability to run batch jobs, so we won’t merely flip all the obtainable trough into scorching standby. Instead, we will keep a shadow cluster for every microservice that we run and inventory that shadow cluster with simply sufficient cases to take the failover visitors for that point of day. The remainder of the cases can be found for batch jobs to make use of as they please.
At the time of failover, as a substitute of the normal scaling technique that triggers AWS to provision cases for us, we inject the cases from the shadow cluster into the dwell cluster. This course of takes about 4 minutes, versus the 35 minutes it used to take.
Since our capability injection is swift, we do not have to cautiously transfer the visitors by proxying to permit scaling insurance policies to react. We can merely change the DNS and open the floodgates, thus shaving much more valuable minutes throughout an outage.
We added filters within the shadow cluster to stop the darkish cases from reporting metrics. Otherwise, they may pollute the metric house and confuse the conventional working habits.
We additionally stopped the cases within the shadow clusters from registering themselves UP in discovery by modifying our discovery consumer. These cases will proceed to stay at midnight (pun absolutely supposed) till we set off a failover.
Now we will do regional failovers in seven minutes. Since we utilized our current reserved capability, we did not incur any further infrastructure prices. The software program that orchestrates the failover is written in Python by a staff of three engineers.
To be taught extra about how Netflix makes use of Python, attend Amjith Ramanujam’s discuss, How Netflix does failovers in 7 minutes flat, at PyCon Cleveland 2018.